In this post, I’ll show you what I did to optimize a REST web service build with Talend ESB using Apache Camel and Apache CXF camel component. In this basic scenario, the web service read records in database using SQL queries (no JPA) and the response will be marshalled, pretty printed and rendered.
Introduction
For this technical demo, I’ll mount a H2 database for testing purpose and launch some performance test using Apache JMeter, the project source code and the JMeter testing project can be found on my github account.
I just want to see the throughput and the average response time then I’ll try to increase it by adding some extra functionalities (or new features), the aim is to improve throughput at its best and response time to the lower possible value.
So I’ll try these following clues, don’t hesitate to give me your own in the comment section 😉 this post still open for an update.
- Changing the camel data format for mashaling/unmarshaling the JSON output, indeed, some framework are faster than other in this task, you check this here.
- Adding new JDBC driver like HirakiCP, according to graphics, not just better than c3p0, Tomcat, vibur, and dbcp2 just amazing.
- Using a cache management like Ehcache, memory or disk caching hits are faster than database hits.
- Unfortunately multithreading is useless in this case, if you have an advice on this, send me a comment.
To be clear, the aim is mainly a developer side improvement, just a quick and dirty proof of concept, for example, to be more accurate it’s better to launch the JMeter test in no gui mode and use a production ready RGDB instead of H2, e.g. you can improve performance with specific parameters like MySQL can do with prepareStatement caching capability.
Test scenario with JMeter
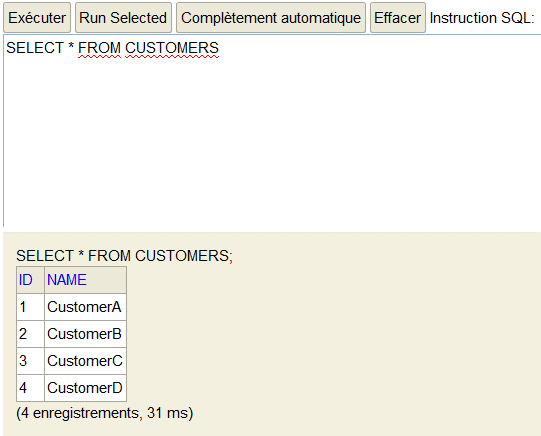
As I previously said, I mounted a H2 database with only one table and 4 test records.
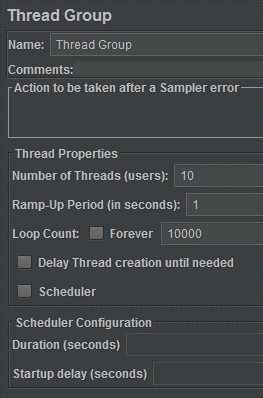
Here is my thread group corresponding to 10 users and 10 thousand calls for each of them.
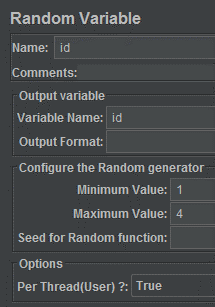
I generate a random id value between 1 and 4.
And finally call the web service with the generated id value.
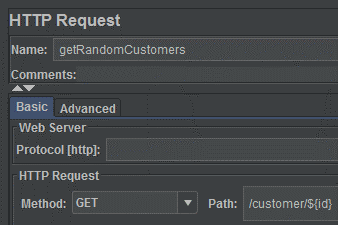
Creating the Camel route
Here is the Camel route, very simple, nothing more and nothing less.
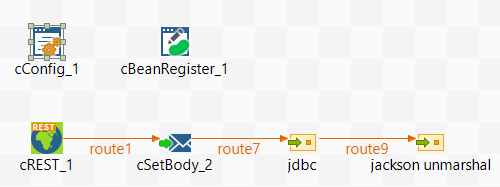

Just change the bindingStyle to simple consumer to get the web service URL parameters values into the header.

I use the message header to directly parse value into the SQL query you build into the body.
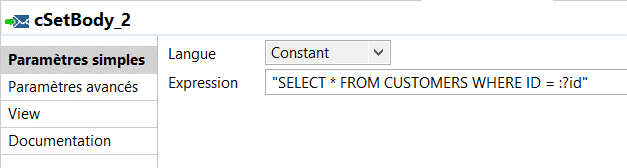
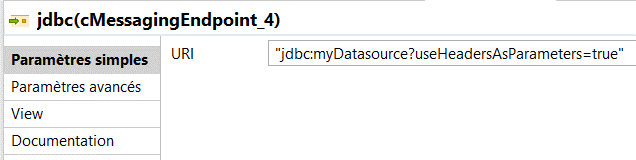
I finally marshal the SQL result with the Camel data format component.

Changing the dataformat
I’ll try three of them, Jackson, XStream and a new challenger named fastjson from Alibaba group existing since the 2.20 of Camel version. Unfortunately I had to create the camel-fastjson-alldep as it’s not already packaged with the Talend 7.1.1 solution, sounds strange but anyway, you can use the Maven assembly plug-in with this dependency
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-fastjson</artifactId>
<version>2.21.2</version>
</dependency>
Let’s see the result with JMeter
Database connection with Spring and Jackson data format

Database connection with Spring and Xstream data format

Database connection with Spring and Fastjson data format

It seems that fastjson is the winner with 550 request by second with a gain of 20%, so I’ll keep it for the next improvement step.
The response time tends to 17ms, not bad, but let see if we can do better 😉
Changing the driver
If you take a look at the HikariCP github page, you’ll see that HikariCP is the perfect challenger and thanks to this good new, there is no source code to change with the camel bean register, only the JDBC connection parameters.
The first attempt was done with the spring transaction manager, as you can see with the bean register component.
See the spring 4 library found on Maven repository, not provided with Talend version 7.
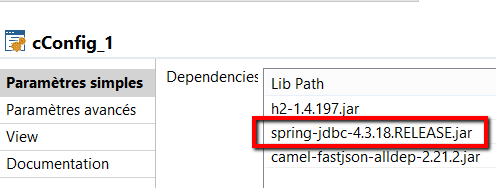
The bean register looks like this for the spring connection, I used the SimpleDriverDataSource recommended by red hat if you plan to deploy this route on an OSGI environment.
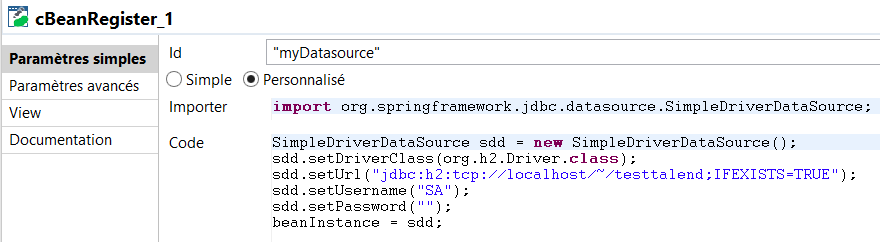
Just add the 143ko library jar you can find here into the cConfig
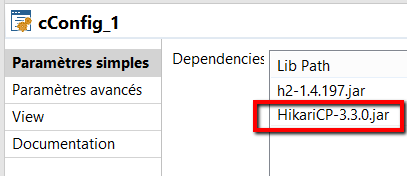
… and change the Camel bean register with the HikariCP parameters, the bean id doesn’t even change 😉

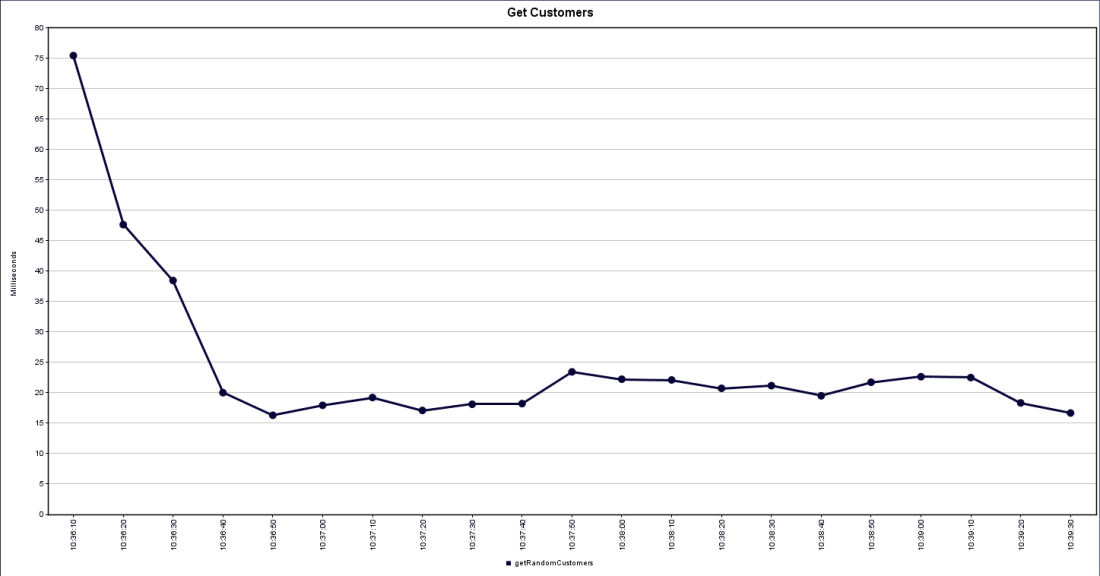
Let’s see the result with JMeter

Simply by changing the JDBC connection pool, we gain 80% with a throughput score of 995 hits/s
The average response time drops to 9ms, better.

Adding a cache manager
Now the route is a little bit more complicated as we have to put and get value from a caching system named Ehcache, apache Camel is able to use it with its dedicated Ehcache component.
For my test, I create a cache on disk located on your user temporary space and a one second time to live, I wanted to simulate a cache expiry in order to make others calls onto the database instead of four calls corresponding to my four poor records.
Changing the Camel route
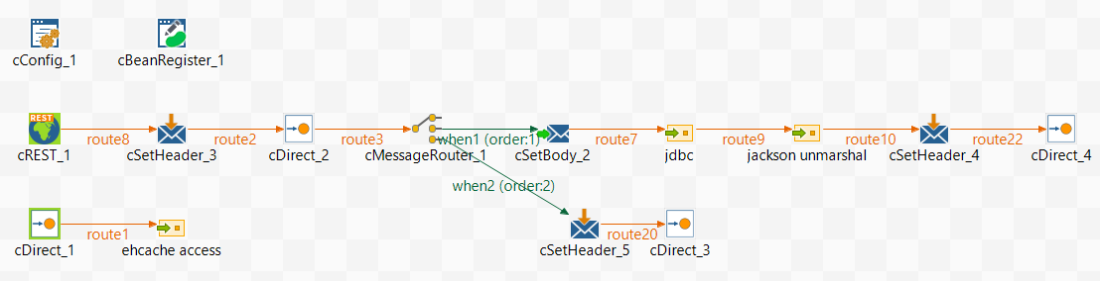
I use a cDirect, the Ehcache endpoint is always the same

Add a resource xml file, this file store all the Ehcache parameters:

Here is the content file
<?xml version=“1.0” encoding=“UTF-8”?>
<config xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”xsi:schemaLocation=“http://www.ehcache.org/v3 http://www.ehcache.org/schema/ehcache-core-3.5.xsd”>
<persistence directory=“${java.io.tmpdir}” />
<cache alias=“dataServiceCache”>
<key-type>java.lang.String</key-type>
<value-type>java.lang.String</value-type>
<expiry>
<ttl unit=“seconds”>1</ttl>
</expiry>
<resources>
<heap unit=“entries”>100</heap>
<disk persistent=“true” unit=“MB”>10</disk>
</resources>
</cache>
</config>
The exchange message header contains keywords you have to customize like CamelEhcacheAction, CamelEhcacheKey and CamelEhcacheValue to make the action and store the key/value, for more informations see the documentation page.
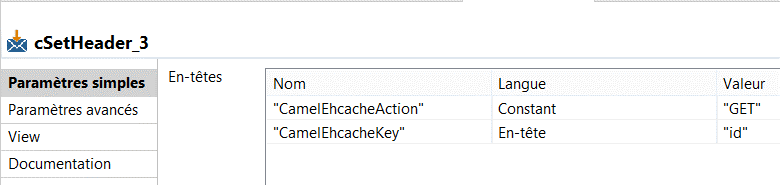
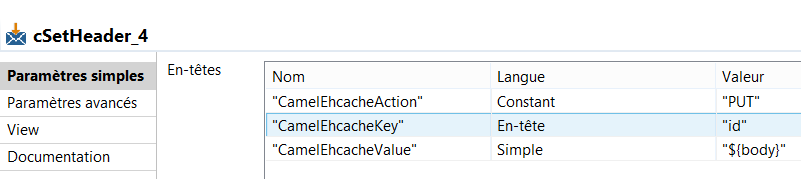
Tips: Define the key value as a String type, more efficient than Object type by default, the throughput will be better.

Let’s see the result with JMeter

Simply by adding a cache manager, we gain another 50% (400% from first try) with a score of 1972 hits/s
The average response time drops again to 4ms !!!

Conclusion
Changing the JDBC driver increase the throughput by 80% and adding a cache manager give me a 400% gain with only 336 hits on the database. Web services are very challenging, as I’m not the ultimate expert, I think again when I start this kind of development. My approach was to merge the best of the examples I could find on the Apache Camel official repository by taking all the best practice. Leave a comment to share your feeling and thanks for reading.