

In the era of big data, real-time data processing is essential for organizations seeking immediate insights and the ability to respond swiftly to changing market conditions. Apache Kafka and Apache Pulsar are two of the most popular platforms for managing streaming data. Their integration with Databricks, a powerful analytics platform built on Apache Spark, enhances these capabilities, providing robust solutions for real-time data management. This article explores the features of Kafka and Pulsar, compares their strengths, and provides guidance on which to choose based on specific use cases.
Apache Kafka: A Standard in Data Streaming
Apache Kafka is a distributed streaming platform originally developed by LinkedIn and later donated to the Apache Software Foundation. Kafka’s architecture is based on a distributed log, where data is written to “topics” divided into partitions.
Topics act as categories for data streams, while partitions are the individual logs that store records sequentially. This division allows Kafka to scale horizontally, enabling high throughput and parallel processing. Partitions also ensure fault tolerance by replicating data across multiple brokers, which maintains data integrity and availability.
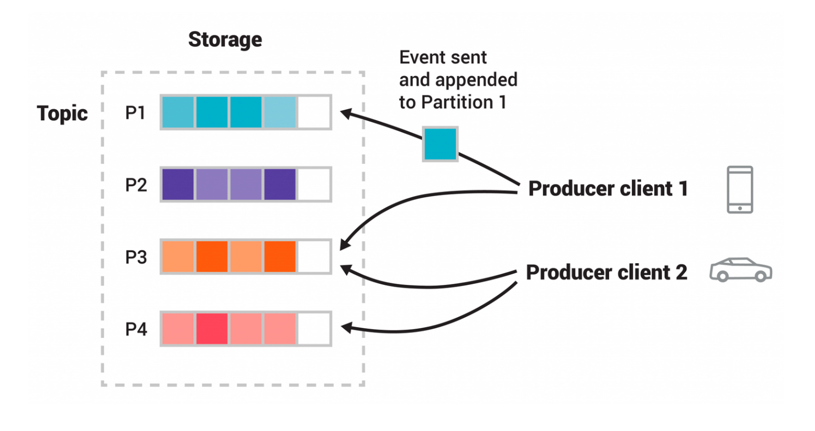
Kafka excels in scenarios that require rapid ingestion and real-time processing of large volumes of data. Its ecosystem includes Kafka Streams for stream processing, Kafka Connect for integrating various data sources, and KSQL for querying data streams with SQL-like syntax. These features make Kafka ideal for applications such as monitoring, log aggregation, and real-time analytics.
Key Features of Kafka:
- High Throughput and Low Latency: Capable of handling millions of messages per second with minimal delay, making it suitable for applications that require quick data processing.
- Durable Storage: Messages can be stored for a configurable retention period, allowing for replay and historical analysis.
- Mature Ecosystem: Includes robust tools for stream processing, data integration, and real-time querying.
Apache Pulsar: The Next Generation of Streaming

Apache Pulsar is a distributed messaging and streaming platform developed by Yahoo and now managed by the Apache Software Foundation. Pulsar’s architecture separates message delivery from storage using a two-tier system comprising Brokers and BookKeeper nodes. This design enhances flexibility and scalability.
Brokers handle the reception and delivery of messages, while BookKeeper nodes manage persistent storage. ZooKeeper plays a crucial role in this architecture by coordinating the metadata and configuration management. This separation allows Pulsar to scale storage independently from message handling, providing efficient resource management and improved fault tolerance. Brokers ensure smooth data flow, BookKeeper nodes ensure data durability, and ZooKeeper maintains system coordination and consistency.
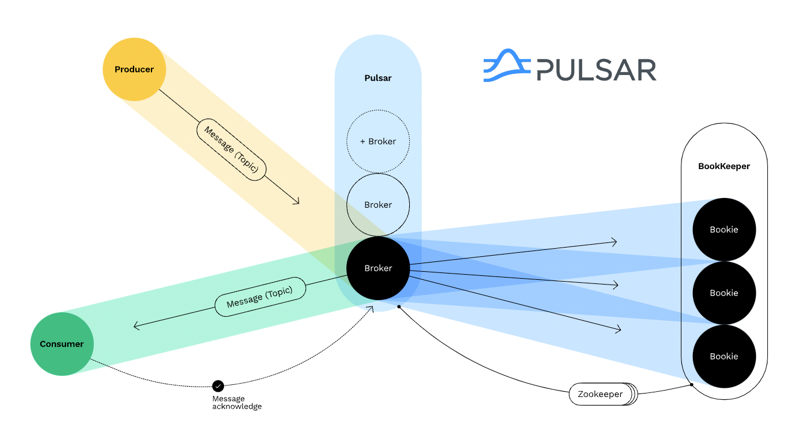
Pulsar supports advanced features such as multi-tenancy, geographic replication, and transaction support. Its multi-tenant capabilities allow multiple teams to share the same infrastructure without interference, making Pulsar suitable for complex, large-scale applications. Additionally, Pulsar supports various APIs and protocols, facilitating seamless integration with different systems.
Key Features of Pulsar:
- Multi-Tenancy: Supports multiple tenants with resource isolation and quotas, providing efficient resource management.
- Advanced Features: Includes geographic replication for data availability across data centers and transaction support for consistent message delivery.
- Flexible Integrations: Supports various APIs and protocols, enabling easy integration with different systems.
Comparing Apache Kafka and Apache Pulsar
While both Kafka and Pulsar are designed for real-time data streaming, they have distinct characteristics that may make one more suitable than the other depending on specific use cases.
Performance and Scalability: Kafka is known for its high throughput and low latency, making it ideal for applications requiring rapid data ingestion and processing. It is well-suited for high-performance use cases where low latency is critical. Pulsar, on the other hand, offers similar performance levels but excels in scenarios requiring multi-tenancy and seamless scaling. Its architecture separating compute and storage makes Pulsar preferable for applications needing flexible scaling and multi-tenant support.
Architecture and Flexibility: Kafka uses a simpler, monolithic architecture which can be easier to deploy and manage for straightforward use cases. This simplicity can be advantageous for quick and efficient setup. In contrast, Pulsar’s two-tier architecture provides more flexibility, especially for applications requiring geographic replication and fine-grained resource management. Pulsar is better suited for complex architectures needing advanced features.
Feature Set: Kafka’s extensive ecosystem, including tools like Kafka Streams, Kafka Connect, and KSQL, makes it a comprehensive solution for stream processing and real-time querying. This makes Kafka ideal for use cases that leverage its mature set of tools. Pulsar includes advanced features like native multi-tenancy, message replication across data centers, and built-in transaction support. These features make Pulsar preferable for applications requiring sophisticated capabilities.
Community and Ecosystem: Kafka has a larger and more mature ecosystem with widespread adoption across various industries, making it a safer bet for long-term projects needing extensive community support. Pulsar, while rapidly growing, offers cutting-edge features particularly appealing for cloud-native and multi-cloud environments. Pulsar is more appropriate for modern, cloud-native applications.
Integration with Databricks
Databricks, built on Apache Spark, leverages both Kafka and Pulsar to provide powerful and scalable real-time data processing capabilities. Here’s how these integrations enhance Databricks:
Databricks offers built-in connectors for reading and writing data directly from & to Kafka, enabling users to build real-time data pipelines using Spark Structured Streaming. This facilitates the transformation and analysis of data streams in real-time.
Similarly, Databricks supports Apache Pulsar, allowing for real-time data streaming with exactly-once processing semantics. Pulsar’s features such as geographic replication and transaction support enhance the resilience and reliability of streaming applications on Databricks.
Benefits of Integration
Integrating Kafka and Pulsar with Databricks provides several benefits. The scalability of both platforms allows for handling large volumes of real-time data without compromising performance. Pulsar’s multi-tenant capabilities and Kafka’s extensive features provide flexible integration tailored to specific business needs. Databricks also offers robust tools for access management and data governance, enhancing the security and reliability of streaming solutions.
Conclusion
Integrating Kafka and Pulsar with Databricks allows organizations to leverage leading streaming technologies to build efficient and scalable real-time data pipelines. By combining the power of Spark with Kafka’s resilience and Pulsar’s flexibility, Databricks provides a robust platform to meet the growing needs of real-time data processing.
For high-speed, low-latency applications, Kafka is the preferred choice. For complex, multi-tenant environments requiring advanced features like geographic replication and transaction support, Pulsar is more suitable.
Author: Pierre-Yves RICHER, Data Engineering Practice Leader at AKABI