

Databricks has emerged as a pivotal platform in the data engineering landscape, offering a comprehensive suite of tools designed to tackle the complexities of data processing, analytics, and machine learning at scale. Among its innovative offerings, Delta Live Tables (DLT) and Unity Catalog stand out as transformative features that significantly enhance the efficiency and reliability of data pipelines. This article delves into these concepts, elucidating their functionalities, benefits, and their particular relevance to data engineers.
Delta Live Tables (DLT): Revolutionizing Data Pipelines
Delta Live Tables is an ETL framework built on top of Databricks, designed to streamline the development and maintenance of data pipelines. With DLT, data engineers can define declarative pipelines that automatically manage complex data transformations, dependencies, and error handling. This high-level abstraction allows engineers to focus on business logic and data transformations rather than the operational complexities of pipeline orchestration.
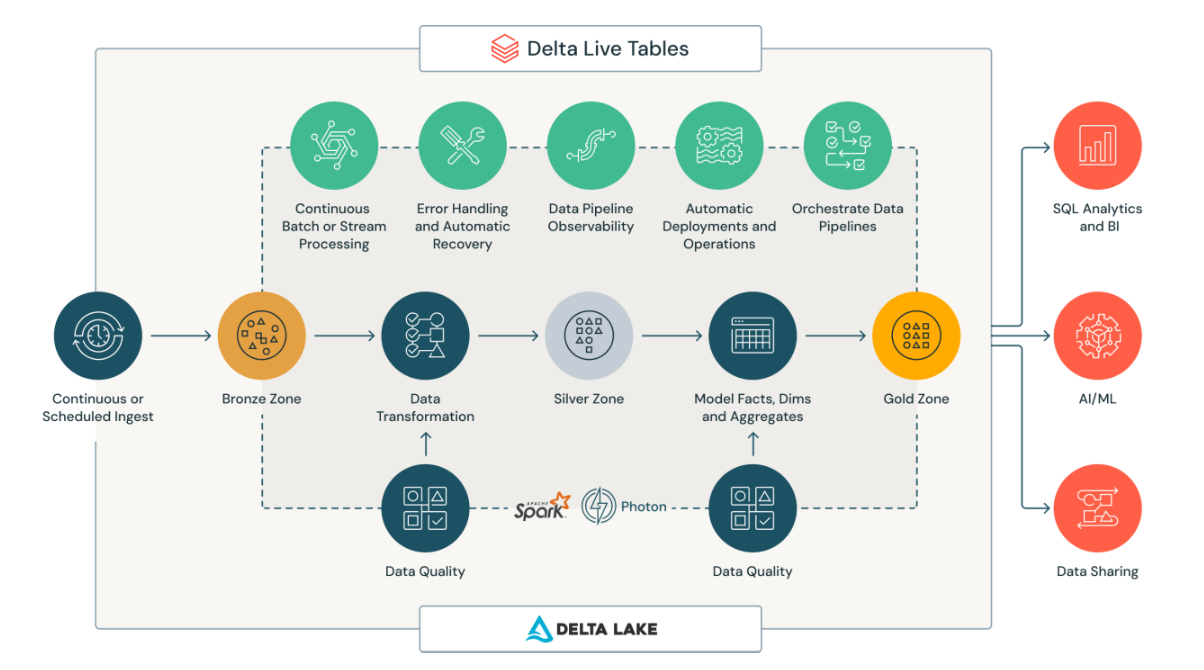
Key Features and Advantages:
- Declarative Syntax: DLT allows data engineers to define transformations using SQL or Python, specifying what the data should look like rather than how to achieve it. This declarative approach simplifies pipeline development and maintenance.
- Automated Error Handling: DLT provides robust error handling mechanisms, including automatic retries, dead-letter queues for unprocessable messages, and detailed error logging. This reduces the time data engineers spend on debugging and fixing pipeline issues.
- Data Quality Controls: With DLT, data engineers can embed data quality checks directly into their pipelines, ensuring that data meets specified quality constraints before it moves downstream. This built-in validation mechanism enhances data reliability and trustworthiness.
- Live Tables: DLT continuously monitors for new data and incrementally updates its outputs, ensuring that downstream users and applications always have access to fresh, high-quality data. This real-time processing capability is crucial for time-sensitive analytics and decision-making.
- Change Data Capture (CDC): DLT supports the capture of changes made to source data, enabling seamless and efficient integration of updates into data pipelines. This feature ensures that data reflects the latest changes, crucial for accurate analytics and real-time reporting.
- Historical and Live Views: Data engineers can create views that either maintain a history of data changes or display the most current data. This allows users to access data snapshots over time or see the present state of data, thereby facilitating thorough analysis and informed decision-making.
Unity Catalog: Centralizing Data Governance
Unity Catalog enhances Databricks by introducing a unified governance framework for all data and AI assets in the Lakehouse, centralizing metadata management, access control, and auditing to streamline data governance and security at scale.
A data catalog acts as an organized inventory for an organization’s data assets, providing metadata, usage, and source information to facilitate data discovery and management. Unity Catalog realizes this by integrating with the Databricks Lakehouse, offering not just a cataloging function but also a unified approach to governance. This ensures consistent security policies, simplifies data access management, and supports comprehensive auditing, helping organizations navigate their data landscape more efficiently and in compliance with regulatory requirements.
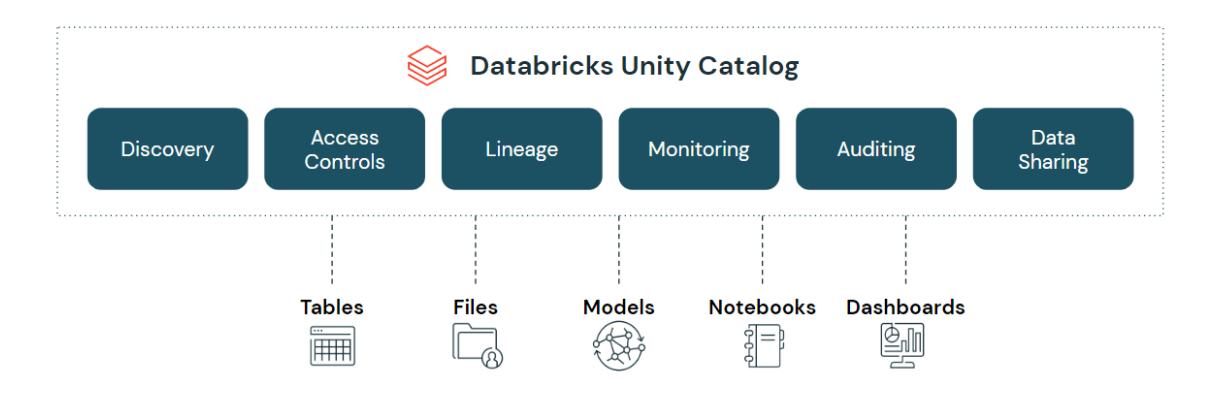
Key Features and Advantages:
- Unified Metadata Management: Unity Catalog consolidates metadata across various data assets, including tables, files, and machine learning models, providing a single source of truth for data governance.
- Fine-grained Access Control: With Unity Catalog, data engineers can define precise access controls at the column, row, and table levels, ensuring that sensitive data is adequately protected and compliance requirements are met.
- Cross-Service Policy Enforcement: Unity Catalog applies consistent governance policies across different Databricks workspaces and services, ensuring uniform security and compliance posture across the data landscape.
- Data Discovery and Lineage: It facilitates easy discovery of data assets and provides comprehensive lineage information, enabling data engineers to understand data origins, transformations, and dependencies. This transparency is vital for troubleshooting, impact analysis, and compliance auditing.
- Auditing: This feature tracks data interactions, offering insights into user activities and changes within the Databricks environment. This facilitates compliance and security by providing a detailed audit trail for accountability and analysis.
Integration: Synergy Between DLT and Unity Catalog
The integration of Delta Live Tables and Unity Catalog within Databricks provides a cohesive and powerful environment for data engineering. DLT’s streamlined pipeline management, combined with Unity Catalog’s robust governance framework, offers a comprehensive solution for building, managing, and securing data pipelines at scale.
- Enhanced Data Reliability: DLT’s real-time processing and data quality checks, coupled with Unity Catalog’s governance capabilities, ensure that data pipelines produce accurate, reliable, and compliant data outputs.
- Increased Productivity: The declarative nature of DLT and the centralized governance of Unity Catalog reduce the complexity and overhead associated with data pipeline development and management, allowing data engineers to focus on delivering value.
- Scalability and Flexibility: Both DLT and Unity Catalog are designed to scale with the needs of the business, accommodating large volumes of data and complex data transformations without sacrificing performance or manageability.
Conclusion: Empowering Data Engineers
For data engineers, the combination of Delta Live Tables and Unity Catalog within Databricks represents a significant leap forward in terms of productivity, data quality, and governance. By abstracting away the complexities of pipeline development and data management, these features allow engineers to concentrate on solving business problems through data. The result is a more efficient, reliable, and secure data infrastructure that can drive insights and innovation at scale. As the data landscape continues to evolve, tools like DLT and Unity Catalog will be indispensable in empowering data engineers to meet the challenges of tomorrow.
It’s important to note that, although Delta Live Tables (DLT) and Unity Catalog are designed to work together seamlessly within the Databricks environment, it’s perfectly viable to pair DLT with a different data cataloging system. This versatility allows organizations to take advantage of DLT’s sophisticated capabilities for automating and managing data pipelines while still utilizing another data catalog that may align more closely with their existing infrastructure or specific needs. Databricks supports this flexible data management strategy, enabling businesses to leverage DLT’s real-time processing and data quality enhancements without being restricted to using only Unity Catalog.
As we explore the horizon of technological innovation, it’s evident that the future is unfolding before us. Engaging with the latest advancements in data management and governance is more than just keeping pace; it’s about seizing the opportunity to redefine how we interact with the vast universe of data. The moment has come to embrace these new possibilities, leveraging their power to drive forward our data-centric initiatives.
Author: Pierre-Yves RICHER, Data Engineering Practice Leader at AKABI