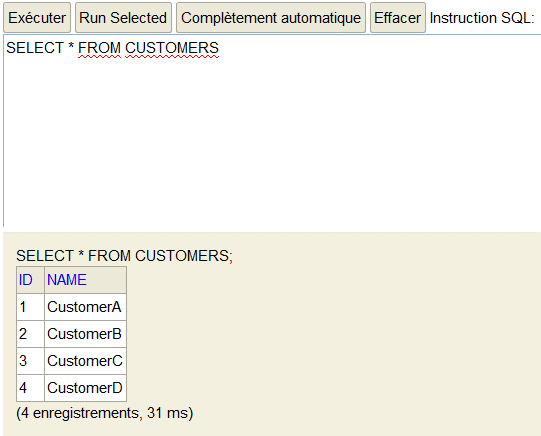
Dataminds Connect 2023, a two-day event taking place in the charming city of Mechelen, Belgium, has proven to be a cornerstone in the world of IT and Microsoft data platform enthusiasts. Partly sponsored by AKABI, this event is a gathering of professionals and experts who share their knowledge and insights in the world of data.
With a special focus on the Microsoft Data Platform, Dataminds Connect has become a renowned destination for those seeking the latest advancements and best practices in the world of data. We were privileged to have some of our consultants attend this exceptional event and we’re delighted to share their valuable feedback and takeaways.
How to Avoid Data Silos – Reid Havens
In his presentation, Reid Havens emphasized the importance of avoiding data silos in self-service analytics. He stressed the need for providing end users with properly documented datasets, making usability a top priority. He suggested using Tabular Editor to hide fields or make them private to prevent advanced users from accessing data not meant for self-made reports. Havens’ insights provided a practical guide to maintaining data integrity and accessibility within the organization.
Context Transition in DAX – Nico Jacobs
Nico Jacobs took on the complex challenge of explaining the concept of “context” and circular dependencies within DAX. He highlighted that while anyone can work with DAX, not everyone can understand its reasoning. Jacobs’ well-structured presentation made it clear how context influences DAX and its powerful capabilities. Attendees left the session with a deeper understanding of this essential language.
Data Modeling for Experts with Power BI – Marc Lelijveld
Marc Lelijveld’s expertise in data modeling was on full display as he delved into various data architecture choices within Power BI. He effortlessly navigated topics such as cache, automatic and manual refresh, Import and Dual modes, Direct Lake, Live Connection, and Wholesale. Lelijveld’s ability to simplify complex concepts made it easier for professionals to approach new datasets with confidence.
Breaking the Language Barrier in Power BI – Daan Lambrechts
Daan Lambrechts addressed the challenge of multilingual reporting in Power BI. While the tool may not inherently support multilingual reporting, Lambrechts showcased how to implement dynamic translation mechanisms within Power BI reports using a combination of Power BI features and external tools like Metadata Translator. His practical, step-by-step live demo left the audience with a clear understanding of how to meet the common requirement of multilingual reporting for international and multilingual companies.
Lessons Learned: Governance and Adoption for Power BI – Paulien van Eijk & Teske van Maaren
This enlightening session focused on the (re)governance and (re)adoption of Power BI within organizations where Power BI is already in use, often with limited governance and adoption. Paulien van Eijk and Teske van Maaren explored various paths to success and highlighted key concepts to consider:
- Practices: Clear and transparent guidance and control on what actions are permitted, why, and how.
- Content Ownership: Managing and owning the content in Power BI.
- Enablement: Empowering users to leverage Power BI for data-driven decisions.
- Help and Support: Establishing a support system with training, various levels of support, and community.
Power BI Hidden Gems – Adam Saxton & Patrick Leblanc
Participating in Adam Saxton and Patrick Leblanc’s “Power BI Hidden Gems” conference was a truly enlightening experience. These YouTube experts presented topics like Query folding, Prefer Dual to Import mode, Model properties (discourage implicit measures), Semantic link, Deneb, and Incremental refresh in a clear and engaging manner. Their presentation style made even the most intricate aspects of Power BI accessible and easy to grasp. The quality of the presentation, a hallmark of experienced YouTubers, made the learning experience both enjoyable and informative.
The Combined Power of Microsoft Fabric for Data Engineer, Data Analyst and Data Governance Manager – Ioana Bouariu, Emilie Rønning and Marthe Moengen
I had the opportunity to attend the session entitled “The Combined Power of Microsoft Fabric for Data Engineer, Data Analyst, and Data Governance Manager”. The speakers adeptly showcased the collaborative potential of Microsoft Fabric, illustrating its newfound relevance in our evolving data landscape. The presentation effectively highlighted the seamless collaboration facilitated by Microsoft Fabric among data engineering, analysis, and governance roles. In our environment, where these roles can be embodied by distinct teams or even a single versatile individual, Microsoft Fabric emerges as a unifying force. Its adaptability addresses the needs of diverse profiles, making it an asset for both specialized teams and agile individuals. Its potential promises to open exciting new perspectives for the future of data management.
Behind the Hype, Architecture Trends in Data – Simon Whiteley
I thoroughly enjoyed Simon Whiteley’s seminar on the impact of hype in technology trends. He offered valuable insights into critically evaluating emerging technologies, highlighting their journey from experimentation to maturity through Gartner’s hype curve model.
Simon’s discussion on attitudes towards new ideas, the significance of healthy skepticism, and considerations for risk tolerance was enlightening. The conclusion addressed the irony of consultants cautioning against overselling ideas, emphasizing the importance of skepticism. The section on trade-offs in adopting new technologies provided practical insights, especially in balancing risk and fostering innovation.
In summary, the seminar provided a comprehensive understanding of technology hype, offering practical considerations for navigating the evolving landscape. Simon’s expertise and engaging presentation style made it a highly enriching experience.
In Conclusion
Dataminds Connect 2023 was indeed a remarkable event that provided valuable insights into the world of data. We want to extend our sincere gratitude to the organizers for putting together such an informative and well-executed event. The knowledge and experiences gained here will undoubtedly contribute to our continuous growth and success in the field. We look forward to being part of the next edition and the opportunity to continue learning and sharing our expertise with the data community. See you next year!
Vincent Hermal, Azure Data Analytics Practice Leader
Pierre-Yves Richer, Azure Data Engineering Practice Leader
avec la participation très précieuse de Sophie Opsommer, Ethan Pisvin, Pierre-Yves Outlet et Arno Jeanjot